为什么需要 RNN?
RNN 处理的对象是时序的数据,这些时序的数据前后之间是存在有某种联系的(例如我们可以根据前后文推断挖掉的某个词)。每一个单词可以使用一个向量来表示,传统的神经网络将这些词一个个的输入网络,是不能得到这种 “前后文” 关系的,所以我们需要一种有记忆的神经网络 - Recurrent Neural network (RNN)
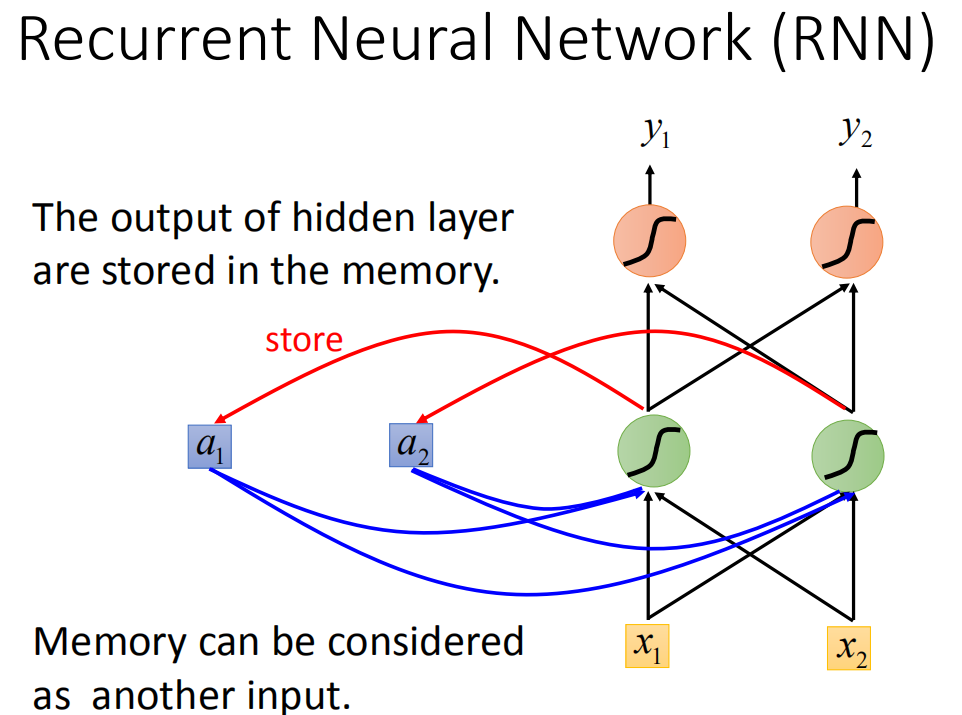
RNN
Elman network
我们只需要对原先的神经网络做一点小小的改动就可以让他拥有 “记忆”。具体来说,我们用一个 memory 区域来保存网络中间层的结果,然后每一次输入数据的时候,网络不仅需要考虑前面的层传过来的参数,还有同时的考虑 memory 区域中的值。比如,我们可以设置每一次中间层的神经元都要将计算得到的结果加上 memory 中的值,这样这一层的神经元就拥有了历史数据的信息。当然,简单的相加是会有很多问题的,这里只是举一个例子。
Jordan network
注意前面说的 Elman network 其实是没有 target 的,我们很难知道把什么东西放到 memory 里面才是比较好的。而 Jordan network 就是把当前的输出存到 memory 里面,然后再下一个节点的时候在读出来,这样我们很就很清楚自己需要放到 memory 里面的是什么东西,从而去优化他。

Bidirectional RNN
前面说的两个网络的 memory,是存储了当前词之前的词的信息,我们很自然的会想到,除了 “前文”,“后文” 的内容也可以充分的利用起来,这就是 Bidirectional RNN

LSTM
LSTM 是什么?
前面的三个 RNN 的网络,存储于 memory 中的值都是设计好的,再一次输入数据的时候都会进行更新。但是在实际操作中我们会有更多的需求,因此我们对需要设立几个 “门” 来控制 memory 中的值以及他什么时候去输出。具体来说,有一个 input gate 控制是否需要将数据输入近 memory,有一个 forget gate 用于控制是否擦除 memory 中的内容,有一个 output gate 用于控制是否输出 memory 中的内容。这里我们可以把控制” 门” 的信号也看做是输入,加上输入的数据 x,LSTM 实际上就是一个输入 4 个 input 产生 1 个 output 的块。
拓展知识 1:Long Short-term Memory 中 - 的正确位置
这个 “-” 应该在 short-term 中间,是长时间的短期记忆。想想我们之前看的 Recurrent Neural Network,它的 memory 在每一个时间点都会被洗掉,只要有新的 input 进来,每一个时间点都会把 memory 洗掉,所以的 short-term 是非常 short 的,但如果是 Long Short-term Memory,它记得会比较久一点 (只要 forget Gate 不要决定要忘记,它的值就会被存起来)。

LSTM 是如何运作的?
假设输入的数据是 z,三个 gate 分别由信号 z~i~,z~f~,z~o~ 控制,首先输入数据会先经过一层激活函数得到 g (z),input gate 的信号在经过一层变换后会得到 f (z~i~),两者相乘就得到了我们想要存入 memory 的数据 $g (z)f (z_i)$(可以认为 f (z~i~) 等于 0 或 1,代表是否存入 memory)。而 forget gate 就决定了是否需要记住 memory 中上一次的数据 c,所以最终存入 memory 的值为 $c’=g (z) f (z_i)+cf (z_f)$,同样的 outout gate 决定了我们是否需要输出 memory 中的值,所以整个 LSTM 最后的输出就可以表示为 $a=h (c’)f(z_o)$。

LSTM meet RNN
这个其实很简单啦,上面整个过程唯一还没有说明的就是,控制三个门的信号是怎么来的?实际上,这三个信号都是由输入经过现象变换得到的

事实上,除了 memory 中的值会让我们获得当前此之前的内容信息之外,LSTM 还会额外的把上一个节点中 LSTM 的一些中间输出取出来,和当前节点的输入 x 拼在一起,然后在用这个拼接的值得到当前节点 LSTM 的四个输入。所以,LSTM 网路的完整结构图应该是介个样子的:

传统 RNN 存在的问题
传统 RNN 的训练其实并没有那么的容易,因为他的 error surface 通常是下面这样的

可以看到,RNN 的 error surface 是非常的崎岖的(一些地方很平坦,突然变的很陡峭)。所以,如果当前位置是在右边的缓坡上,这样因为梯度很小,我们会把学习率设置成一个较大的值,而随着我们在坡面上不断的下行,很有可能我们会一脚踩在这个悬崖上,这样悬崖处的梯度是很大的,这时候的学习率也很大,我们下一次的落脚的位置,就会非在十万八千里外了。这一点也很好解决,我们可以设置一个阈值,超过了这个阈值梯度都设置为同意的值,这样即使踩在了悬崖上,也不会飞的很远,这就是 Clipping 技术。
拓展阅读 2:如何得到梯度的大小?
可以用 “对于输入变化,输出变化的剧烈程度” 来表示梯度的大小
RNN VS LSTM
RNN 的 error surface 为什么会这么崎岖呢?在 RNN 当中,每一个数据都可以影响 memory 中的值。所以在每一个节点数据输入的时候,memory 中的值会被完全的覆盖掉。但是在 LSTM 中,对于一个新的 input,我们会把原来的 memory 乘上一个值再加上 input。这样做首先保证了如果一个节点对 memory 产生了影响,这种影响会一直存在于 memory 中;此外,memory 和 input 是相加的,不像 RNN 在输入新的 input 后会强制刷新 memory。
GRU
相比于 lstm,Gates Recurrent Unit (GRU) 只有两个 Gate。其实这两个 Gate 也并不是那么神秘,只不过他对 input gate 和 forget gate 做了一个联动,即当 input gate 打开的时候,forget gate 会自动的关闭;当 forget gate 没有要刷新 memory 中的值,input gate 就会关起来。也就是说要把 memory 里面的值清楚掉,才放新的值进来
后面的内容都是关于 RNN 的实际应用的,还蛮好玩的,感兴趣的可以看视频做进一步的了解 https://www.bilibili.com/video/BV1JE411g7XF?p=21
