我们知道计算机中存储数据都是用二进制的 0 或 1 表示的,那么假设现在有两个词:奔驰、宝马,我们怎样去表示这两个词呢?
一种很简单直观的方法就是使用数字序号,也就是 1 表示奔驰,2 表示宝马。这种序号表示会隐含的加入一些模糊的信息,比如 2-1=1 是否就代表宝马 - 奔驰 = 奔驰呢?或者 2>1 是否表示宝马比奔驰要好呢?显然,我们希望这两者是一个并列的关系,而表示两者不相关的一个很好的方法就是使用正交向量,这就是 one-hot 形式。两个单词的 one-hot 形式表示如下:
| 词语 | ||
|---|---|---|
| 奔驰 | 0 | 1 |
| 宝马 | 1 | 0 |
使用 one-hot 形式的向量就已经可以提取出一些文本特征,比如简单的相加就可以获得每个单词出现的次数。
直接把 one-hot 形式的词表示输入神经网络是否可行呢?答案是否定的。one-hot 的正交形式走向了另一个极端,某些词之间确实是存在有某种联系的。例如 “喜欢” 和 “爱” 虽然是两个不同层面的词,但确实都表达了某种正向的情感,我们希望他们的向量表示可以和类似于” 讨厌 “一类的词尽可能的远一点。这种单词间的远近,我们可以使用两个向量点积的形式来表示 ——a^T^b,而在 one-hot 形势下,我们很容易的得到任意两个单词间的距离都为 0。此外,这样的表示方法需要我们预先知道所有需要表示的单词总数,光是新华词典的单字已经够多了,他们所能组合成的词更是另一个量级,这样就会导致每一个词都需要用一个很长很长的向量来表示,这样不仅带来了庞大的计算量,也不利于越来越多新词的出现。
于是,word2vec(word to vector) 的方法就应运而生了!这种方法的思路也很简单:既然原来的 one-hot 太大了,我们就用一个更低维度的向量来表示这个单词;既然 one-hot 正交的过于绝对了,我们就改变每个维度的值来更好的表示这个词。当然,降维也不是说降就降的,我们需要给模型提供更多的信息。大家应该都做过英语的完形填空,给定背景和上下文,即使中间挖掉了一个词,我们也可以推理出这个词或者其他相近的词,这也是我们需要额外给模型提供的信息 —— 上下文。怎么表示上下文呢?我们可以用当前单词的前几个词或者后几个词来作为他的上下文信息,这里的” 几个 “就是滑动窗口的大小。有了上下文后,我们只要把他丢入一个简单的,只有一层隐藏层的神经网络,以上下文为输入,预测的单词为输出,不断的去训练,最后取出中间的隐藏层,就可以得到单词的词向量啦!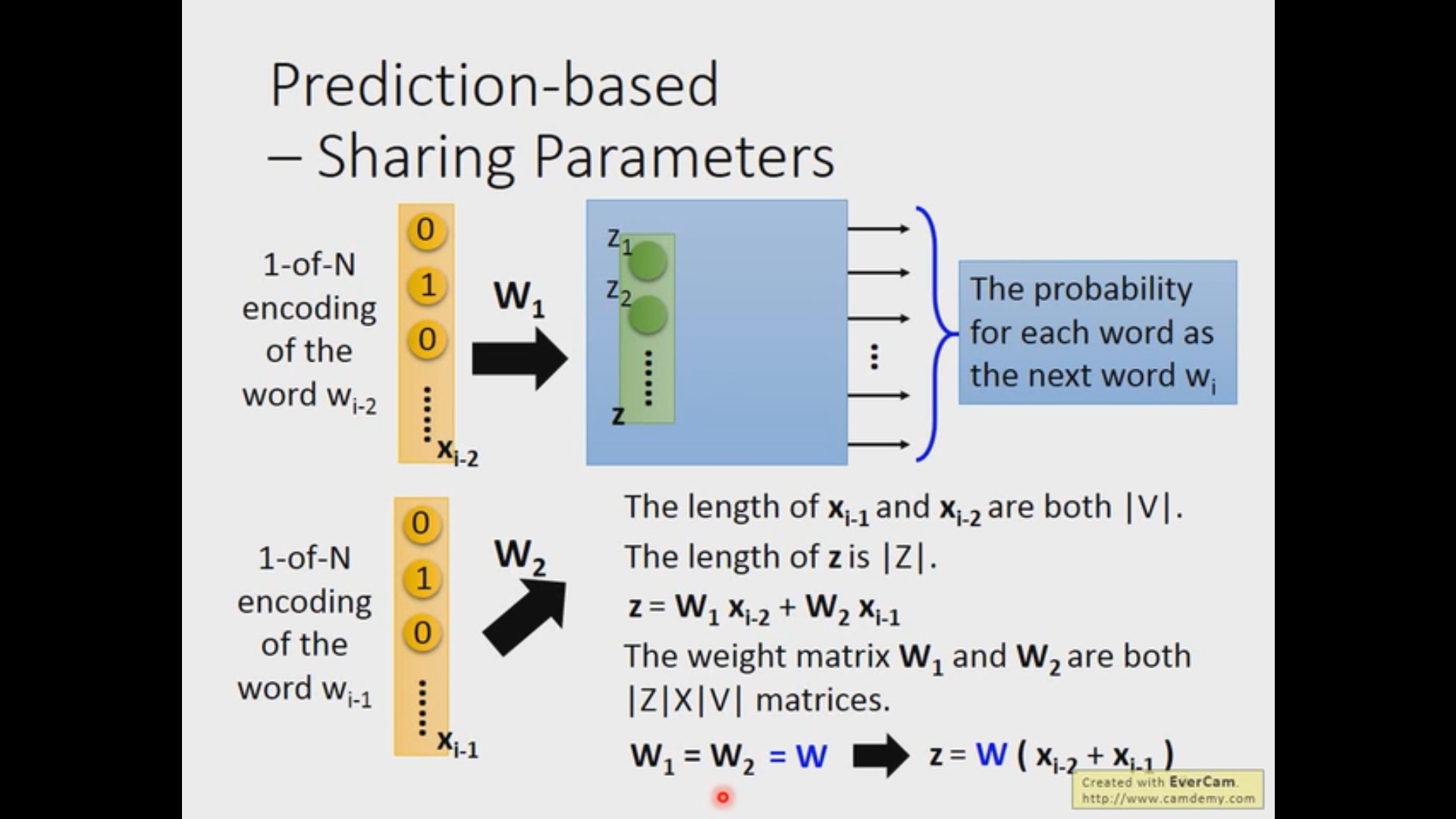
让我们来拆解一下这个训练过程。首先我们拥有的数据是各个不同单词的 one-hot 的向量,我们希望网络可以输出一个更低维度的向量来表示某个单词。我们所选取的网络,是一个只拥有一个中间层的全连接网络,这个中间层神经元的个数,就代表了我想要的词向量的维度。为了利用上下文的信息,在输入层会有 n 个单词,怎么输入网络呢?有一种方法是把这些向量拼成一个长长的列向量,但实际上,我们会把这些词向量相同位置所对应的中间层相同的位置所用的权重是一样的。可以设想一下如果每一个位置的权重都不一样,那么同一个词放到不同的位置,他得到的结果就是不同的(这里我们不需要考虑序列先后的问题),而且,采用权重相同的方法可以大大的降低参数量(类似于卷积操作)。在这种情况下,每个单词的 W 相同,所以中间层的输出 z 可以通过 $W (x_{i-2}+x_{i-1}+・・・x_0)$ 得到。
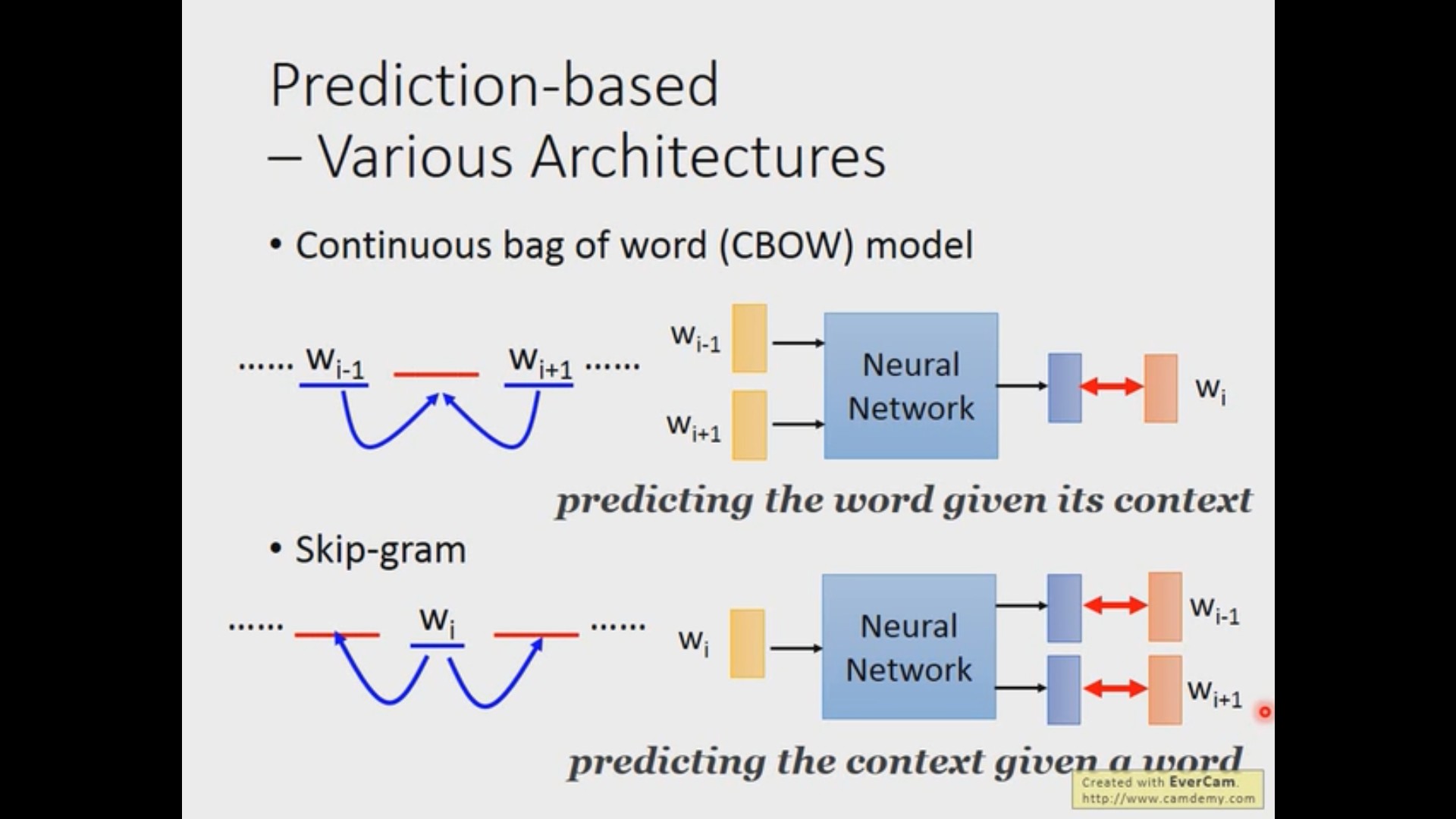
拓展知识 1:上下文的其他表示
在上面的例子中,其实只用了当前词的前面几个词来预测。除此之外,我们还可以使用前后的几个词来预测当前此(CBOW)或者是用当前词来预测前后的其他词(Skip-gram)
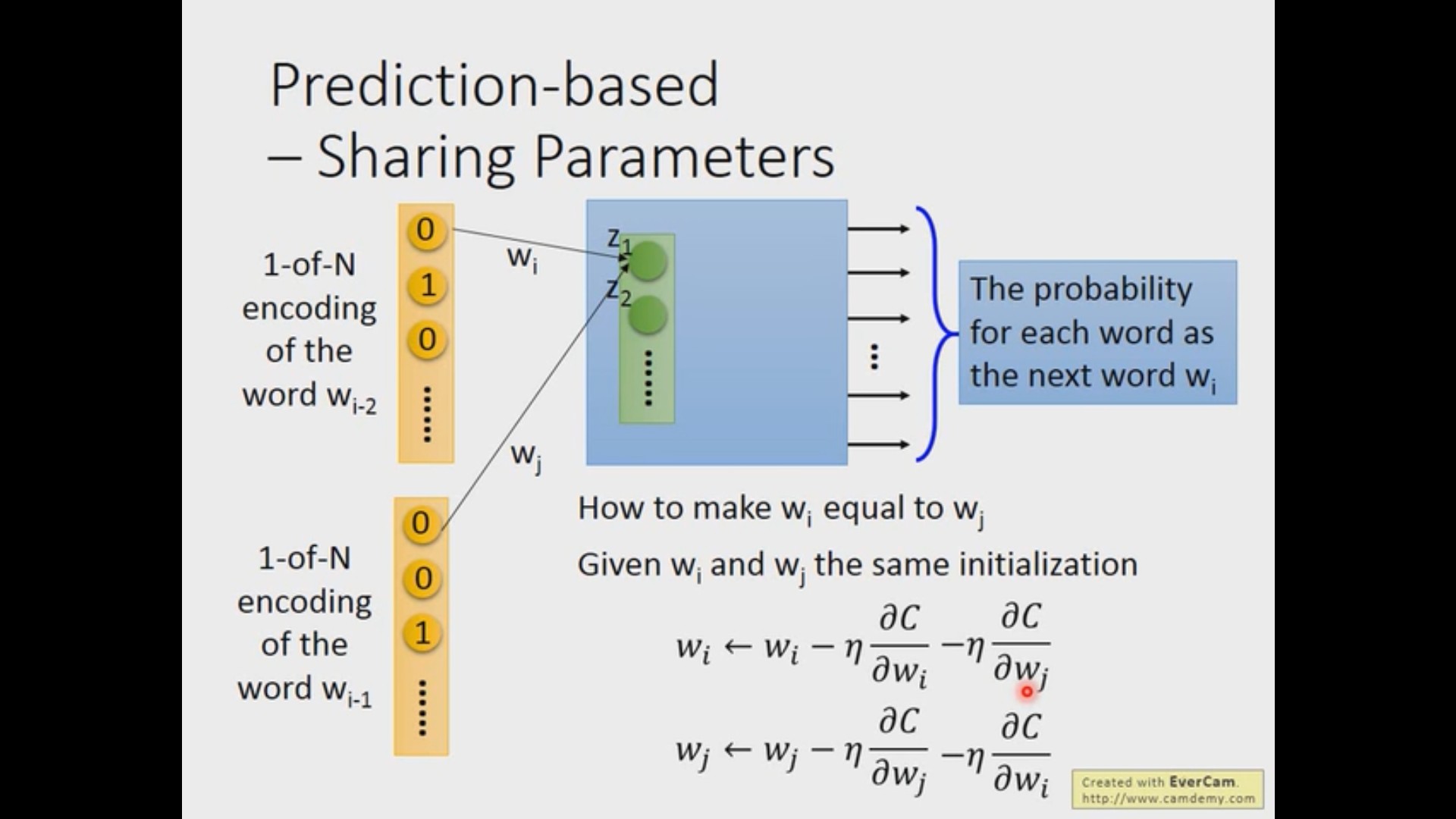
拓展知识 2:如何控制两个 weight 在训练过程中一样?
上述的方法因为对输入的所有权重值都是一样的,所以问题得到了简化。但在实际操作中,可能会存在希望两个输入的某几个 weight 相同的情况。方法其实很简单,只需要将他们的初始值设为一样,并在权重更新的时候同时减去两者计算得到的梯度。
当然还有很多有意思的事情可以做,关于多语言嵌入、多域嵌入、文档嵌入等内容的更多介绍请参照李宏毅老师的课程 https://www.bilibili.com/video/BV1JE411g7XF?p=22
