To store English words, one method is to use linked lists and store a word letter by letter. To save some space, we may let the words share the same sublist if they share the same suffix. For example, loading and being are stored as showed in Figure 1.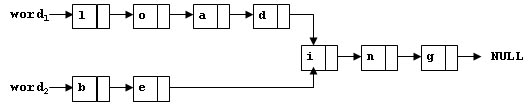
You are supposed to find the starting position of the common suffix (e.g. the position of i in Figure 1).
Input Specification:
Each input file contains one test case. For each case, the first line contains two addresses of nodes and a positive N (≤10^5^), where the two addresses are the addresses of the first nodes of the two words, and N is the total number of nodes. The address of a node is a 5-digit positive integer, and NULL is represented by −1.
Then N lines follow, each describes a node in the format:Address Data Next
whereAddress is the position of the node, Data is the letter contained by this node which is an English letter chosen from { a-z, A-Z }, and Next is the position of the next node.
Output Specification:
For each case, simply output the 5-digit starting position of the common suffix. If the two words have no common suffix, output -1 instead.
Sample Input:
1 | 11111 22222 9 |
Sample Output:
1 | 67890 |
Sample Input 2:
1 | 00001 00002 4 |
Sample Output 2:
1 | -1 |
浅析
观察题目所给的数据格式,不同于传统的找字串,实际上题目考察的是静态链表。又由于字串的特性,只需要找到第一个相同的地址即可。可以设置 flag 位,另链表 1 的 flag 全为 true, 若在链表 2 中能找到 flag 为 1 的结点,就是两者的子串。
Code
1 |
|
