GAN
GAN 简介
生成式对抗网络 (Generative adversarial networks,GANs) 的核心思想源自于零和博弈,包括生成器和判别器两个部分。生成器接收随机变量并生成 “假” 样本,判别器则用于判断输入的样本是真实的还是合成的。两者通过相互对抗来获得彼此性能的提升。判别器所作的其实就是一个二分类任务,我们可以计算他的损失并进行反向传播求出梯度,从而进行参数更新。

GAN 的优化目标可以写作:
$$
\large {\min_G\max_DV(D,G)= \mathbb{E}{x\sim p{data}}[\log D(x)]+\mathbb{E}_{z\sim p_z(z)}[log(1-D(G(z)))]}
$$
其中 $\log D (x)$ 代表了判别器鉴别真实样本的能力,而 $D (G (z))$ 则代表了生成器欺骗判别器的能力。在实际的训练中,生成器和判别器采取交替训练,即先训练 D,然后训练 G,不断往复。
WGAN
在上一部分我们给出了 GAN 的优化目标,这个目标的本质是在最小化生成样本与真实样本之间的 JS 距离。但是在实验中发现,GAN 的训练非常的不稳定,经常会陷入坍缩模式。这是因为,在高维空间中,并不是每个点都可以表示一个样本,而是存在着大量不代表真实信息的无用空间。当两个分布没有重叠时,JS 距离不能准确的提供两个分布之间的差异。这样的生成器,很难 “捕捉” 到低维空间中的真实数据分布。因此,WGAN (Wasserstein GAN) 的作者提出了 Wasserstein 距离 (推土机距离) 的概念,其公式可以进行如下表示:
$$
W(\mathbb P_r,\mathbb P_g)=\inf_{\gamma\sim\prod{\mathbb P_r,\mathbb P_g}}\mathbb E_{(x,y)~\gamma}[|x-y|]
$$
这里 $\prod {\mathbb P_r,\mathbb P_g}$ 指的是真实分布 $\mathbb P_r$ 和生成分布 $\mathbb P_g$ 的联合分布所构成的集合,$(x,y)$ 是从 $\gamma$ 中取得的一个样本。枚举两者之间所有可能的联合分布,计算其中样本间的距离 $|x-y|$,并取其期望。而 Wasserstein 距离就是两个分布样本距离期望的下界值。这个简单的改进,使得生成样本在任意位置下都能给生成器带来合适的梯度,从而对参数进行优化。
DCGAN
卷积神经网络近年来取得了耀眼的成绩,展现了其在图像处理领域独特的优势。很自然的会想到,如果将卷积神经网络引入 GAN 中,是否可以带来效果上的提升呢?DCGAN (Deep Convolutional GANs) 在 GAN 的基础上优化了网络结构,用完全的卷积替代了全连接层,去掉池化层,并采用批标准化 (Batch Normalization,BN) 等技术,使得网络更容易训练。

用 DCGAN 生成图像
为了更方便准确的说明 DCGAN 的关键环节,这里用一个简化版的模型实例来说明。代码基于 pytorch 深度学习框架,数据集采用 MNIST
1 | import torch |
判别器 & 生成器
判别器使用 LeakyReLU 作为激活函数,最后经过 Sigmoid 输出,用于真假二分类
生成器使用 ReLU 作为激活函数,最后经过 tanh 将输出映射在 $[-1,1]$ 之间
1 | # 构建判别器 |
训练模型
1 | # 使用GPU |
可视化结果
1 | reconsPath = './gan_samples/fake_images-200.png' |
cGAN
在之前介绍的几种模型中,我们注意到生成器的输入都是一个随机的噪声。可以认为这个高维噪声向量提供了一些关键信息,而生成器根据自己的理解将这些信息进行补充,最终生成需要的图像。生成器生成图片的过程是完全随机的。例如上述的 MNIST 数据集,我们不能控制它生成的是哪一个数字。那么,有没有方法可以对其做一定的限制约束,来让生成器生成我们想要的结果呢?cGAN (Conditional Generative Adversarial Nets) 通过增一个额外的向量 y 对生成器进行约束。以 MNIST 分类为例,限制信息 y 可以取 10 维的向量,对于类别进行 one-hot 编码,并与噪声进行拼接一起输入生成器。同样的,判别器也将原来的输入和 y 进行拼接。作者通过各种实验证明了这个简单的改进确实可以起到对生成器的约束作用。

判别器 & 生成器
只需要在前向传播的过程中加入限制变量 y,我们很容易就能得到 cGAN 的生成器和判别器模型
1 | class Discriminator(nn.Module): |
Pix2Pix
在上面的 cGAN 例子中,我们的控制信息取的是想要图像的标签,如果这个控制信息更加的丰富,例如输入一整张图像,那么它能否完成一些更加高级的任务?Pix2Pix (Image-to-Image Translation with Conditional Adversarial Networks) 将这一类问题归纳为图像到图像的翻译,其使用改进后的 U-net 作为生成器,并设计了新颖的 Patch-D 判别器结构来输出高清的图像。Patch-D 是指,不管网络所使用的输入图像有多大,都将其切割成若干个固定大小的 Patch,判别器只需对这些 Patch 的真假进行判断。因为 L1 损失已经可以衡量生成图像和真实图像的全局差异,所以作者认为判别器只需要用 Patch-D 这样更关注于局部差异的结构即可。同时 Patch-D 的结构使得网络的输入变小,减少了计算量并且增大了框架的扩展性。

CycleGAN
Pix2Pix 虽然可以生成高清的图像,但其存在一个致命的缺点:需要相互配对的图片 x 与 y。在现实生活中,这样成对的图片很难或者根本不可能搜集到,这就大大的限制了 Pix2Pix 的应用。对此,CycleGAN (Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks) 提出了不需要配对的图像翻译方法。
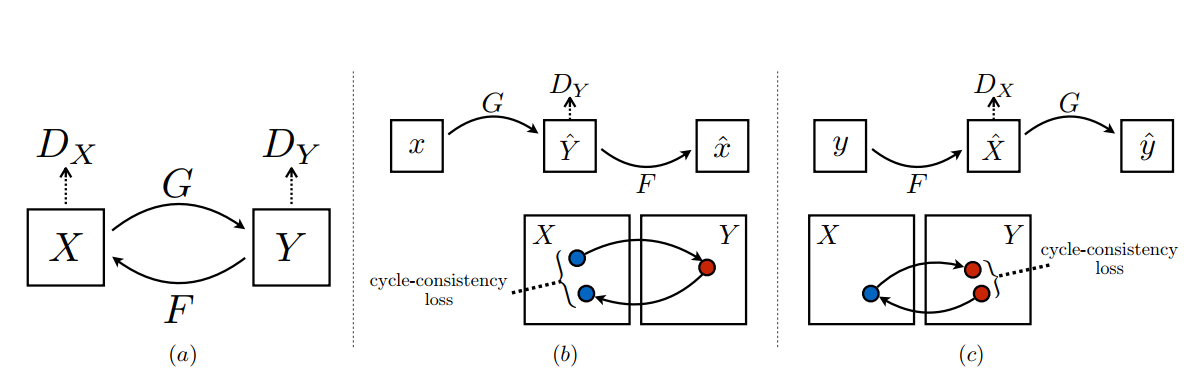
CycleGAN 其实就是一个 X->Y 的单向 GAN 上再加一个 Y->X 的单向 GAN,构成一个 “循环”。网络的结构和单次训练过程如下(图片来自于量子位):


除了经典的基础 GAN 损失之外,CycleGAN 还引入了 Consistency loss 的概念。循环一致损失使得 X->Y 转变的过程中必须保留有 X 的部分特性。循环损失的公式如下:
$$
L_{cyc}(G,F)=\mathbb E_{x\sim p_{data}(x)}[|F(G(x))-x|1]+\mathbb E{y\sim p_{data}(y)}[|G(F(x))-y| 1]
$$
两个判别器的损失表示如下:
$$
\textit{L}{GAN}(G,D_Y,X,Y)=\mathbb E_{y\sim p_{data}(y)}[logD_Y(y)]+\mathbb E_{x\sim p_{data}(x)}[log(1-D_Y(G(x)))]
$$
$$
\textit{L}_{GAN}(F,D_X,Y,X)=\mathbb E_{x\sim p_{data}(x)}[logD_X(x)]+\mathbb E_{y\sim p_{data}(y)}[log(1-D_X(F(y)))]
$$
最后网络的优化目标可以表示为
$$
\min _{G_{X\rightarrow Y},G_{Y\rightarrow X}}\max_{D_X,D_Y} L(G,F,D_x,D_y)=L_{GAN}(G,D_Y,X,Y)+L_{GAN}(F,D_X,Y,X)+\lambda L_{cyc}(G,F)
$$
Pix2Pix 以及 CycleGAN 的官方复现入口:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
StarGAN
Pix2Pix 解决了有配对图像的翻译问题,CycleGAN 解决了无配对图像的翻译问题,然而他们所作的图像到图像翻译,都是一对一。假设现在需要将人脸转换为喜怒哀乐四个表情,那么他们就需要进行 4 次不同的训练,这无疑会耗费巨大的计算资源。针对于这个问题,StarGAN (StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation) 借助 cGAN 的思想,在网络输入中加入一个域的控制信息。对于判别器,其不仅需要鉴别样本是否真实,还需要判断输入的图像来自哪个域。StarGAN 的训练过程如下:
- 将原始图片 $c$ 和目标生成域 $c$ 进行拼接后丢入生成器得到生成图像 $G (x,c)$
- 将生成图像 $G (x,c)$ 和真实图像 $y$ 分别丢入判别器 D,判别器除了需要判断输入图像的真伪之外,还需要判断它来自哪个域
- 将生成图像 $G (x,c)$ 和原始生成域 $c’$ 丢入生成器生成重构图片 (为了对生成器生成的图像做进一步的限制,与 CycleGAN 的重构损失类似)

了解了 StarGAN 的训练过程,我们很容易得到其损失函数各项的表达形式
首先是 GAN 的一般损失,这里作者采用了前文所述的 WGAN 的损失形式:
$$
L_{adv}=\mathbb E_x[D_{src}(x)]-\mathbb E_{x,c}[D_{src}(G(x,c)))]-\lambda_{gp}\mathbb E_{\hat x}[(|\nabla \hat xD{src}(\hat x)| 2-1)^2]
$$
对于判别器,我们需要鼓励其将输入图像正确的分类到目标域 c‘(原始生成域):
$$
L{src}^r=\mathbb E_{x,c’}[-logD_{cls}(c’|x)]
$$
对于生成器,我们需要鼓励其成功欺骗判别器将图片分类到目标域 c(目标生成域),此外,生成器还需要在以生成图像和原始生成域 c’的输入下成功将图像还原回去,这两部分的损失表示如下:
$$
L_{src}^f=\mathbb R_{x,c}[-logD_{cls}(c|G(x,c))]
$$
$$
L_{rec}=\mathbb E_{x,c,c’}[|x-G(G(x,c),c’)|_1]
$$
各部分损失乘上自己的权重加总后就构成了判别器和生成器的总损失:
$$
L_D=-L_{adv}+\lambda_{cls}L_{cls}^{r}
$$
$$
L_G=L_{adv}+\lambda_{cls}L_{clas}^f+\lambda_{rec}L_{rec}
$$
此外,为了更具备通用性,作者还加入了 mask vector 来适应不同的数据集之间的训练。
总结
| 名称 | 创新点 |
|---|---|
| DCGAN | 首次将卷积神经网络引入 GAN 中 |
| cGAN | 通过拼接标签信息来控制生成器的输出 |
| Pix2Pix | 提出了一种图像到图像翻译的通用方法 |
| CycleGAN | 解决了 Pix2Pix 需要图像配对的问题 |
| StarGAN | 提出了一种一对多的图像到图像的翻译方法 |
| InfoGAN | 基于 cGAN 改进,提出一种无监督的生成方法,适用于不知道图像标签的情况 |
| LSGAN | 用最小二乘损失函数代替原始 GAN 的损失函数,缓解了训练不稳定、生成图像缺乏多样性的问题 |
| ProGAN | 在训练期间逐步添加新的高分辨率层,可以生成高分辨率的图像 |
| SAGAN | 将注意力机制引入 GAN 当中,简约高效利用了全局信息 |
本文列举了生成式对抗网络在发展过程中一些具有代表性的网络结构。GANs 如今已广泛应用于图像生成、图像去噪、超分辨、文本到图像的翻译等各个领域,且在近几年的研究中涌现了很多优秀的论文。感兴趣的同学可以从下面的链接中 pick 自己想要了解的 GAN~
- THE-GAN-ZOO:汇总了各种 GAN 的论文及代码地址。
- GAN Timeline:按照时间线对不同的 GAN 进行了排序。
- Browse state-of-the-art:将 ArXiv 上的最新论文与 GitHub 代码相关联,并做了比较排序,涉及了深度学习的各个方面。
参考文献
- Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
- Arjovsky M, Chintala S, Bottou L. Wasserstein gan[J]. arXiv preprint arXiv:1701.07875, 2017.
- Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv preprint arXiv:1511.06434, 2015.
- Mirza M, Osindero S. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
- Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
- Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
- Choi Y, Choi M, Kim M, et al. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8789-8797.
- Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2794-2802.
- Karras T, Aila T, Laine S, et al. Progressive growing of gans for improved quality, stability, and variation[J]. arXiv preprint arXiv:1710.10196, 2017.
- Chen X, Duan Y, Houthooft R, et al. Infogan: Interpretable representation learning by information maximizing generative adversarial nets[C]//Advances in neural information processing systems. 2016: 2172-2180.
- Zhang H, Goodfellow I, Metaxas D, et al. Self-attention generative adversarial networks[C]//International Conference on Machine Learning. 2019: 7354-7363.
